
Cog: A Code Generation Tool Written in Python
| Category: | Software Development, Business |
|---|---|
| Keywords: | Code Generation, Database, XML, Collaboration Support, Groupware |
| Title: | Cog: A Code Generation Tool Written in Python |
| Author: | Ned Batchelder |
| Date: | 2004-06-01 |
| Website: | http://www.nedbatchelder.com/ |
| Website: | http://www.kubisoftware.com/ |
| Summary: | Cog, a general-purpose Python-based code generation tool, is used to speed development of a collaboration system written in C++. |
| Logo: |
Introduction
Cog is a simple code generation tool written in Python. We use it or its results every day in the production of Kubi.
Kubi is a collaboration system embodied in a handful of different products. We have a schema that describes the representation of customers' collaboration data: discussion topics, documents, calendar events, and so on. This data has to be handled in many ways: stored in a number of different data stores, shipped over the wire in an XML representation, manipulated in memory using traditional C++ objects, presented for debugging, and reasoned about to assess data validity, to name a few.
We needed a way to describe this schema once and then reliably produce executable code from it.
The Hard Way with C++
Our first implementation of this schema involved a fractured collection of representations. The XML protocol module had tables describing the serialization and deserialization of XML streams. The storage modules had other tables describing the mapping from disk to memory structures. The validation module had its own tables containing rules about which properties had to be present on which items. The in-memory objects had getters and setters for each property.
It worked, after a fashion, but was becoming unmanageable. Adding a new property to the schema required editing ten tables in different formats in as many source files, as well as adding getters and setters for the new property. There was no single authority in the code for the schema as a whole. Different aspects of the schema were represented in different ways in different files.
We tried to simplify the mess using C++ macros. This worked to a degree, but was still difficult to manage. The schema representation was hampered by the simplistic nature of C++ macros, and the possibilities for expansion were extremely limited.
The schema tables that could not be created with these primitive macros were still composed and edited by hand. Changing a property in the schema still meant touching a dozen files. This was tedious and error prone. Missing one place might introduce a bug that would go unnoticed for days.
Searching for a Better Way
It was becoming clear that we needed a better way to manage the property schema. Not only were the existing modifications difficult, but new areas of development were going to require new uses of the schema, and new kinds of modification that would be even more onerous.
We'd been using C++ macros to try to turn a declarative description of the schema into executable code. The better way to do it is with code generation: a program that writes programs. We could use a tool to read the schema and generate the C++ code, then compile that generated code into the product.
We needed a way to read the schema description file and output pieces of code that could be integrated into our C++ sources to be compiled with the rest of the product.
Rather than write a program specific to our problem, I chose instead to write a general-purpose, although simple, code generator tool. It would solve the problem of managing small chunks of generator code sprinkled throughout a large collection of files. We could then use this general purpose tool to solve our specific generation problem.
The tool I wrote is called Cog. Its requirements were:
- We needed to be able to perform interesting computation on the schema to create the code we needed. Cog would have to provide a powerful language to write the code generators in. An existing language would make it easier for developers to begin using Cog.
- I wanted developers to be able to change the schema, and then run the tool without having to understand the complexities of the code generation. Cog would have to make it simple to combine the generated chunks of code with the rest of the C++ source, and it should be simple to run Cog to generate the final code.
- The tool shouldn't care about the language of the host file. We originally wanted to generate C++ files, but we were branching out into other languages. The generation process should be a pure text process, without regard to the eventual interpretation of that text.
- Because the schema would change infrequently, the generation of code should be an edit-time activity, rather than a build-time activity. This avoided having to run the code generator as part of the build, and meant that the generated code would be available to our IDE and debugger.
Code Generation with Python
The language I chose for the code generators was, of course, Python. Its simplicity and power are perfect for the job of reading data files and producing code. To simplify the integration with the C++ code, the Python generators are inserted directly into the C++ file as comments.
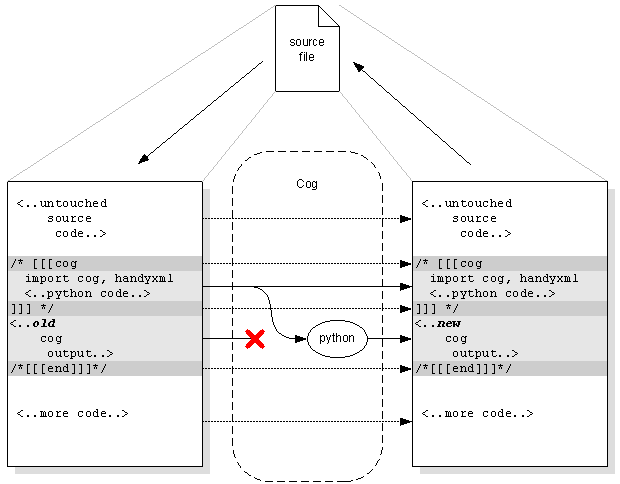
Cog reads a text file (C++ in our case), looking for specially-marked sections of text, that it will use as generators. It executes those sections as Python code, capturing the output. The output is then spliced into the file following the generator code.
Because the generator code and its output are both kept in the file, there is no distinction between the input file and output file. Cog reads and writes the same file, and can be run over and over again without losing information.
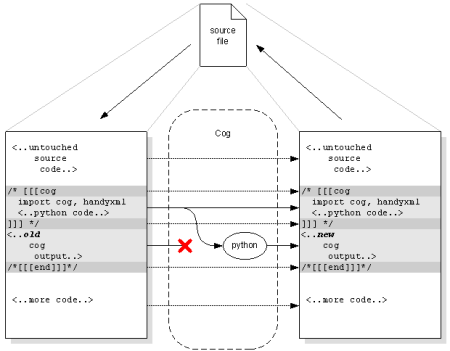
Cog processes text files, converting specially marked sections of the file into new content without disturbing the rest of the file or the sections that it executes to produce the generated content. Zoom in
{kind=link}
In addition to executing Python generators, Cog itself is written in Python. Python's dynamic nature made it simple to execute the Python code Cog found, and its flexibility made it possible to execute it in a properly-constructed environment to get the desired semantics. Much of Cog's code is concerned with getting indentation correct: I wanted the author to be able to organize his generator code to look good in the host file, and produce generated code that looked good as well, without worrying about fiddly whitespace issues.
Python's OS-level integration let me execute shell commands where needed. We use Perforce for source control, which keeps files read-only until they need to be edited. When running Cog, it may need to change files that the developer has not edited yet. It can execute a shell command to check out files that are read-only.
Lastly, we used XML for our new property schema description, and Python's wide variety of XML processing libraries made parsing the XML a snap.
An Example
Here's a concrete but slightly contrived example. The properties are described in an XML file:
<!-- Properties.xml -->
<props>
<property name='Id' type='String' />
<property name='RevNum' type='Integer' />
<property name='Subject' type='String' />
<property name='ModDate' type='Date' />
</props>
We can write a C++ file with inlined Python code:
// SchemaPropEnum.h
enum SchemaPropEnum {
/* [[[cog
import cog, handyxml
for p in handyxml.xpath('Properties.xml', '//property'):
cog.outl("Property%s," % p.name)
]]] */
// [[[end]]]
};
After running this file through Cog, it looks like this:
// SchemaPropEnum.h
enum SchemaPropEnum {
/* [[[cog
import cog, handyxml
for p in handyxml.xpath('Properties.xml', '//property'):
cog.outl("Property%s," % p.name)
]]] */
PropertyId,
PropertyRevNum,
PropertySubject,
PropertyModDate,
// [[[end]]]
};
The lines with triple-brackets are marker lines that delimit the sections Cog cares about. The text between the [[[cog and ]]] lines is generator Python code. The text between ]]] and [[[end]]] is the output from the last run of Cog (if any). For each chunk of generator code it finds, Cog will:
- discard the output from the last run,
- execute the generator code,
- capture the output, from the cog.outl calls, and
- insert the output back into the output section.
How It Worked Out
In a word, great. We now have a powerful tool that lets us maintain a single XML file that describes our data schema. Developers changing the schema have a simple tool to run that generates code from the schema, producing output code in four different languages across 50 files.
Where we once used a repetitive and aggravating process that was inadequate to our needs, we now have an automated process that lets developers express themselves and have Cog do the hard work.
Python's flexibility and power were put to work in two ways: to develop Cog itself, and sprinkled throughout our C++ source code to give our developers a powerful tool to turn static data into running code.
Although our product is built in C++, we've used Python to increase our productivity and expressive power, ease maintenance work, and automate error-prone tasks. Our shipping software is built every day with Python hard at work behind the scenes.
More information, and Cog itself, is available at http://www.nedbatchelder.com/code/cog
About the Author
Ned Batchelder is a professional software developer who struggles along with C++, using Python to ease the friction every chance he gets. A previous project of his, Nat's World *was the subject of an earlier Python Success Story.*