Mod_python [1] is an Apache server [2] module that embeds the Python interpreter within the server and provides an interface to Apache server internals as well as a basic framework for simple application development in this environment. The advantages of mod_python are versatility and speed.
This paper describes mod_python with the focus on the implementation, its philosophy and challenges.
It is intended for an audience already familiar with web application development in general and Apache in particular, as well as preferably mod_python itself. Knowledge of C and some understanding of Python internals is helpful as well.
Quite simply - it is integration of Python and Apache. Apache is a sort of a Swiss knife of web serving, especially the upcoming 2.0 version, which does not limit itself to HTTP but can serve any protocol for which there exists a module. Mod_python aims to provide direct access to the riches of this functionality for Python developers.
While speed is definitely a key benefit of mod_python and is taken very seriously during design decisions, it would be wrong to identify it as the sole reason for mod_python's existence.
At least for now, providing "inline Python" type functionality a lá PHP [15] is not a goal of this project. This is because the integration with Apache can still use a lot of improvement, and there does not seem to be a clear consensus within the Python community on how to embed Python code in HTML, with quite a few modules floating around, each doing it their own way.
Mod_python was initially released in April 2000 as a replacement for an earlier project called Httpdapy [3] (1998), which in turn was a port to Apache of Nsapy [4] (1997). Nsapy was based on an embedding example by Aaron Watters in the Internet Programming with Python [5] book.
Mod_python is stable enough to be used in production. The latest stable version at the time of this writing is 2.7.6. This version is written for 1.3 version of the Apache server. All of the development effort these days is focused on the next major version of mod_python, 3.0, which will support the upcoming Apache 2.0.
Mod_python consists of two components - an Apache dynamically
loadable module mod_python.so (this module can also be
statically linked into Apache) and a Python package mod_python.
Assuming that mod_python is loaded into Apache, consider this configuration excerpt:
DocumentRoot /foo/bar
<Directory /foo/bar>
AddHandler python-program .py
PythonHandler hello
</Directory>
The following script named hello.py resides in the /foo/bar
directory:
from mod_python import apache
def handler(req):
req.send_http_header()
req.write("hello %s" % req.remote_host)
return apache.OK
A request to http://yourdomain/somefile.py would result
in a page showing "hello 1.2.3.4" where
1.2.3.4 is the IP of the client.
Just about every mod_python script begins with "from
mod_python import apache". apache is a
module inside the mod_python package that provides the
interface to Apache constants (such as OK) and many
useful functions. Note also the Request object req,
which provides information about the current request, the connection
and an interface to more internal Apache functions, in this example
send_http_header() to send HTTP headers and write()
method to send data back to the client.
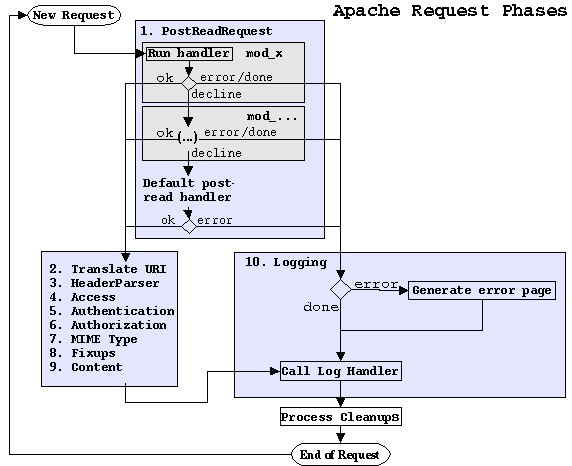
Apache processes incoming requests in phases. A phase is one of a series of small tasks that each need to take place to service a request. For example, there is a phase during which a URI is mapped to a file on disk, a phase during which authentication happens, a phase to generate the content, etc. Altogether, Apache 1.3 has 10 phases (11 if you consider clean-ups a phase).
The key architectural feature of the Apache server is that it can allow a module to process any phase of a request. This way a module can augment the server behavior in any way whatsoever. (module in this context does not refer to a Python module; an Apache module is usually a shared library or DLL that gets loaded at server startup, though modules can also be statically linked with the server).
Mod_python is an Apache module. What makes it different from most other Apache modules is that it itself doesn't do anything, but provide the ability to do what Apache modules written in C do to be done in Python. To put it another way, it delegates phase processing to user-written Python code.
This figure shows a diagram of Apache request processing.
Each Apache module can provide a handler function for any of the request processing phases. There are 4 types of return values possible for every handler.
DECLINED means the module declined to handle this phase, Apache moves to the next module in the module list.
OK means that this phase has been processed, Apache will move on to the next phase without giving any more modules an opportunity to handle this phase.
An error return (which is any HTTP [7] error constant) will cause Apache to produce an error page and jump to the Logging phase.
A special value of DONE means the whole request has been serviced, Apache will jump to the Logging phase.
The DECLINED return is somewhat deceiving, because many modules actually perform some action and then return DECLINED to give other modules an opportunity to handle the phase. The example below illustrates how the DECLINED return can be used in a handler that inserts a silly reply header into every request:
from mod_python import apache
def fixup(req):
req.headers_out["X-Grok-this"] = "Python-Psychobabble"
return apache.DECLINEDAt this point it should be a bit clearer how this functionality is different from CGI environment. Comparing CGI with mod_python is not very meaningful, because the scope of CGI is much narrower. One difference is that CGI is intended exclusively for dynamic content generation, which is not a requirement for mod_python scripts. For example, consider a mod_python script that implements a custom logging mechanism for the entire server, which plays no role in content generation.
Apache request processing makes use of a few important C structures, access to which is available through mod_python.
request_rec - the Request Recordrequest_rec is probably the largest and most
frequently encountered structure. It contains all the information
associated with processing a request (about 50 members total).
Mod_python provides a wrapper around request_rec, a
built-in type mp_request. The mp_request
type is not meant to be used directly. Instead, each mod_python
handler gets a reference to an instance of a Request
class, a regular Python class which is a wrapper around mp_request
(which is a wrapper around request_rec). This is so that
mod_python users could attach their own attributes to the Request
instance as a way to maintain state across different phases.
The Request class provides methods for sending
headers and writing data to the client.
conn_rec - the Connection Recordconn_rec keeps all the information associated with
the connection. It is a separate structure from request_rec
because HTTP [7] allows for multiple requests
to be serviced over the same connection.
The connection record is accessible in mod_python through the
mp_conn built-in type, a reference to which is always
available via connection member of the Request
object (req.connection).
server_rec - the Server Recordserver_rec keeps all the information associated with
the virtual server, such as the server name, its IP, port number,
etc. It is available via the server member of the
Request object (req.server).
ap_table - Apache tableAll key/value lists (for example RFC 822 [8] headers) in Apache are stored in tables. A table is a construct very similar to a Python dictionary, except that both keys and values must be strings, key lookups are case insensitive and a table can have duplicate keys. Internally, Apache tables differ from Python dictionaries in that lookups do not using hashing, but rather a simple sequential search (although there was a proposal to use hashing in Apache 2.0).
Mod_python provides a wrapper for tables, an mp_table
object, which acts very much like a Python dictionary. If there are
duplicate keys, mp_table will return a list. To allow
addition of duplicate keys, mp_table provides an add()
method.
Here is some code to illustrate how mp_table acts:
from mod_python import apache
def handler(req):
t = apache.make_table()
t["Set-Cookie"] = "Foo: bar;"
t.add("Set-Cookie") = "Bar: foo;"
s = t["Set-Cookie"] # s is ["Foo: bar;", "Bar: foo;"]
return apache.DECLINEDThe Python C API has a function to initialize a sub-interpreter,
Py_NewInterprer(). Here is an excerpt from the Python/C
API Reference manual [6] documenting this function:
Create a new sub-interpreter. This is an (almost) totally separate environment for the execution of Python code. In particular, the new interpreter has separate, independent versions of all imported modules, including the fundamental modules __builtin__ , __main__ and sys . The table of loaded modules (sys.modules) and the module search path (sys.path) are also separate. The new environment has no sys.argv variable. It has new standard I/O stream file objects sys.stdin, sys.stdout and sys.stderr (however these refer to the same underlying FILE structures in the C library).
This valuable feature of Python is not available from within Python itself, so most Python users are not even aware of it. But it makes good sense to take advantage of this functionality for mod_python, where one Apache process can be responsible for any number of unrelated applications at the same time. By default, mod_python creates a subinterpreter for each virtual server, but this behavior can be altered.
When a subinterpreter is created, a reference to it is saved in a Python dictionary keyed by subinterpreter names, which are always strings. This dictionary is internal to mod_python.
During phase processing, prior to executing the user Python code,
mod_python has to decide which interpreter to use. By default, the
interpreter name will be the name of the virtual server, which is
available via req->server->server_hostname Apache
variable. If the PythonInterpPerDirectory is On,
then the name of the interpreter will be the directory being accessed
(from req->filename), and with
PythonInterpPerDirective On,
the directory where the Python*Handler directive currently
in effect is specified (which can be some parent directory). The
interpreter name can also be forced using PythonInterpreter
directive.
Once mod_python has a name for the interpreter, we check the dictionary of subinterpreters for this name, if it exists, we switch to it, else a new subinterpreter is created.
After mod_python has been given control by Apache to process a phase of a request, it steps through the following actions. (This is a simplified list.)
Determine the interpreter to use by looking at directives currently in effect, possibly the server name and the directory.
Get/Create a subinterpreter.
Get/Create a CallBack object. The CallBack object is a Python object whose methods provide all the functionality implemented in Python.
Create an mp_request object. (for performance
reasons mp_conn and mp_server objects are
created on-demand, so if the user code never refers to them they
would never be created)
Call CallBack.Dispatch() passing it a reference
to mp_request and the name of the phase being
processed.
(From here on all the processing is done in Python rather than C)
Instantiate a Request object, a wrapper around
mp_request.
Set up sys.path
by prepending (if not already there) the directory being accessed.
Import (or if modification date is later than the last import, reload) the Python module specified in the configuration.
Locate the handler function/object inside the module.
Call the user
function/object passing it a reference to Request
object.
Return the return value to mod_python.
(At this point execution moves back from Python to C)
Mod_python returns the return value and control to Apache.
Memory management is always a challenge for long running processes. One has to be very careful to always remember to free all memory allocated during request processing, no matter what errors take place.
To combat this problem, Apache provides memory pools. The
Apache API has a rich set of functions for allocating memory,
manipulating strings, lists, etc., and each of these functions always
takes a pool pointer. For example, instead of allocating memory using
malloc() et al, Apache modules allocate memory using
ap_palloc() and passing it a pool pointer. All memory
allocated in such a way can then be freed at once by destroying the
pool. Apache creates several pools with varying lifetimes, and
modules can create their own pools as well. The pool probably used
the most is the request pool, which is created for every request and
is destroyed at the end of the request.
Unfortunately, the Python interpreter cannot use Apache pools. So for the most part, mod_python programmer is at the mercy of the Python reference counting and garbage collecting mechanism (or lack thereof). In most cases it works just fine. In those cases where you do see the Apache process growing the simplest solution is to configure the server to recycle itself every few thousand requests using the MaxRequestsPerChild directive.
Apache provides API's to execute cleanup functions just before a
pool is destroyed. A cleanup is registered by calling the
ap_register_cleanup() C function which takes three
arguments: a pool pointer, a function pointer, and a void pointer to
some arbitrary data. Just before the pool is destroyed, the function
will be called and passed the pointer as the only argument.
Mod_python uses cleanups internally to destroy mp_request
and mp_tables.
Cleanups are available to mod_python users via
Request.register_cleanup() and
request.server.register_cleanup(). The former runs after
every request, the latter runs when the server exits.
As an astute reader probably noticed, mod_python (or rather
Apache) associates a handler with a directory (SetHandler) or
a file type (AddHandler), but not a specific file. In the
quick example in the beginning of this paper it really doesn't matter
what file is being accessed in the "/foo/bar" directory.
For as long as it ends with .py, same hello handler will
be invoked always yielding the same result. In fact the file referred
to in the URI doesn't even need to exist.
A natural question would then be "Why can't I access multiple mod_python scripts in one directory?" (or "This isn't very useful!"). The answer here is that mod_python expects there to be an intermediate layer between it and the application. This layer (handler) is up to the user's imagination, but a couple of functional handlers (standard handlers) is bundled with mod_python.
This handler is for users who want to use their existing CGI code with mod_python. This handler sets up a fake CGI environment and runs the user program. A couple of interesting implementation challenges were encountered here.
At first, this handler used to set up the CGI environment through
the standard os.environ object. For whatever reason
(Python bug?) this frequent environment manipulation introduced a
memory leak (about a kilobyte per request), so as a quick hack,
os.environ was replaced with a regular dictionary
object. This works fine for the most part, but is a problem for
scripts that use environment as a way to communicate with
subsequently called programs, notably some database interfaces which
expect database server information in an environment variable.
Another problem was that since cgihandler uses import/reload to
run a module, "indirect" module imports by the "main"
module would become noops after the first hit. This became a problem
for users who expected the top level code in those indirectly
imported modules to be executed for every hit. To solve this problem,
cgihandler now examines the sys.modules variable before
and after importing the user scripts, and in the end, deletes any
newly appeared modules from sys.modules, causing those
modules to be imported again next time.
Last but not the least, the CGI specification [14] strongly recommends that the server set the current directory to the directory in which the script is located. There is no thread safe way of changing the current directory and so the cgihandler uses a thread lock in multithreaded environment (e.g. Win32) which is held for as long as the script runs essentially forcing the server to process one cgihandler request at a time.
Given all of the above problems, the cgihandler is not a recommended development environment, but is regarded as a stop gap measure for users who have a lot of legacy CGI code, and should be used with caution and only if really necessary.
The publisher handler is probably the best way to start writing web applications using mod_python. The functionality of the publisher handler was inspired by the ZPublisher, a component of Zope [10].
The idea is that a URI is mapped to some object inside a module, the "/" in the URI having the same meaning as a "." in Python. So http://somedomain/somedir/module/object/method would invoke method method of object object inside module module in directory somedir, and the return value of the method would be sent to the client.
Here is a "hello world" example:
def hello(req, who="nobody"):
return "Hello, %s!" % who
If the file containing this code is called myapp.py in
directory somedir, then hello function can
be accessed via http://somedomain/somedir/myapp/hello which should
result in a page showing "Hello, nobody!", whereas
http://somedomain/somedir/myapp/hello?who=John should result in
"Hello, John!".
Note that the first argument is a Request object,
which means all the advanced mod_python functionality is still
available when using the publisher handler.
Debugging mod_python applications can be difficult. Mod_python provides support for the Python debugger (pdb) via the PythonEnablePdb configuration directive, but its usability is limited because the debugger is an interactive tool that uses standard input and output and therefore can only be used when Apache is running in foreground mode (-X switch in Apache 1.3 or -DONE_PROCESS in 2.0).
Mod_python sends any traceback information to the server log, and with PythonDebug directive set to On (default is Off), the traceback information is sent to the client.
For programmers who like to use the print statement
as a debugging tool, the technique favored by the author is to
instead raise a variable optionally surrounded by "`"
(back quotes) from any point in the code with the PythonDebug
directive On. This will make
the value of the variable appear on the browser and is as effective
as print.
Mod_python is thread-safe and runs fine on Win32, where Apache is multithreaded.
One should be careful to make sure that any extension modules that an application uses are thread-safe as well. For example, many database access drivers on Windows are not thread safe, and some kind of a thread lock needs to be used to make sure no two threads try to run the driver code in parallel.
Interestingly, the Python interpreter itself isn't completely thread safe, and to run multiple threads it maintains a thread lock that is released every 10 Python bytecode instructions to let other threads run. If any, the negative impact of that is most likely negligible.
Those familiar with mod_perl [10] will notice that some functionality of mod_python is remarkably similar to mod_perl, for example the names of the Apache configuration directives are exactly the same except the word Perl is substituted for Python.
It would be wrong not to say that much of mod_python functionality, especially in the area of Apache configuration, was intentionally made functionally similar to mod_perl. Under the hood they have next to nothing in common, mainly because Perl and Python interpreters are quite different.
There were good reasons for similarities though. First, there is no sense in reinventing the wheel - mod_perl has encountered and solved many problems just as applicable to mod_python. Second, since both projects had similar goals, except the language of choice was different, it made sense to keep the outside look consistent, especially the Apache configuration. Oftentimes the person who has to deal with the Apache config is a System Administrator, not a programmer, and consistency would make SysAdmin's job easier.
In a web application environment speed and low overhead are extremely important. Many people don't appreciate how really important it is until their site gets featured on another big volume site (the so called "/. effect") but instead of getting lots of hard earned publicity, they get a bunch of frustrated web surfers trying to get to a site so overloaded that no one can access it.
Considering this angle, C always wins over Python. If the author of mod_python had more time, a much larger percentage of mod_python would be implemented in C. But given the length of time it takes to write quality C code, initially a decision was made to implement in C only those parts which cannot be done in Python.
SWIG [13] was given some consideration as a tool to provide the mapping to Apache C structures (such as request_rec). There are a few problems with SWIG. The main advantages of SWIG are speed and ease with which an interface to a C library can be created. The resulting C code is not necessarily meant to be easy to read, and SWIG itself becomes yet another tool that is required for compilation in an already pretty complicated build environment. Altogether, for a long-term project like mod_python, where quality is more important than the timeline, SWIG does not seem to be the right choice.
As has been mentioned before, the main focus of development today
is compatibility with Apache 2.0. Apache 2.0 is architecturally quite
a bit different from its predecessor (1.3), so much so that it would
not be very easy or practical to try to write code that works with
both 1.3 and 2.0. It is possible, but the code becomes a tangle of
#ifedef statements because the majority of the API
functions have been renamed. So the next major version of mod_python
will support Apache 2.0 only.
Apache 2.0 is actually a combination of two software packages. One is the server itself, the other is the underlying library, the Apache Portable Runtime (APR) [12]. The APR is a general purpose library designed to provide functionality common in daemons of all kinds and to abstract the OS specifics (thus "Portable"). Future versions of mod_python will eventually provide an interface to large part or perhaps all of the APR.
Another big improvement in 2.0 is the introduction of filters and connection handlers. The alpha version of mod_python 3.0 already supports filters. (A filter would be the right place to implement inline Python). A connection handler is a handler at a level below HTTP. Using a connection handler one could implement an entirely different protocol, e.g. FTP. At the time of this writing mod_python 3.0 alpha does not support connection handlers, but such support is in the plans.
[1] Mod_python. http://www.modpython.org/
[2]
Apache Http Server. http://httpd.apache.org/
[3]
Httpdapy. http://www.ispol.com/home/grisha/httpdapy
[4]
Nsapy. http://www.ispol.com/home/grisha/nsapy
[5]
Aaron Watters, Guido van Rossum, James C. Ahlstrom, Internet
Programming with Python, M&T Books, 1996.
[6] Guido van
Rossum, Fred L. Drake, Jr, Python/C API Reference Manual, PythonLabs.
http://www.python.org/doc/current/api/.
[7] R. Fielding, UC Irvine, J. Gettys, J. Mogul, DEC, H. Frystyk,
T. Berners-Lee, MIT/LCS, "Hyper Text Transfer Protocol --
HTTP/1.1", RFC 2068, IETF January 1997.
http://www.ietf.org/rfc/rfc2068.txt
[9]
Crocker, D., "Standard for the Format of ARPA Internet Text
Messages", STD 11, RFC 822, UDEL, August 1982.
http://www.ietf.org/rfc/rfc822.txt
[10]
Zope http://www.zope.org/
[11]
Mod_perl, Apache/Perl Integration. http://perl.apache.org/
[12]
Apache Portable Runtime. http://apr.apache.org/
[13]
Simplified Wrapper and Interface Generator. http://www.swig.org/
[14]
Ken A L Coar, The WWW Common Gateway Interface Version 1.1.
http://cgi-spec.golux.com/draft-coar-cgi-v11-03.txt
[15] PHP. http://www.php.net/